
- English
- 简体中文
Today, we’re excited to announce the very first release of Toolathlon — a benchmark designed to quantitatively evaluate how well LLM agents perform on long‑horizon tasks across diverse, realistic scenarios.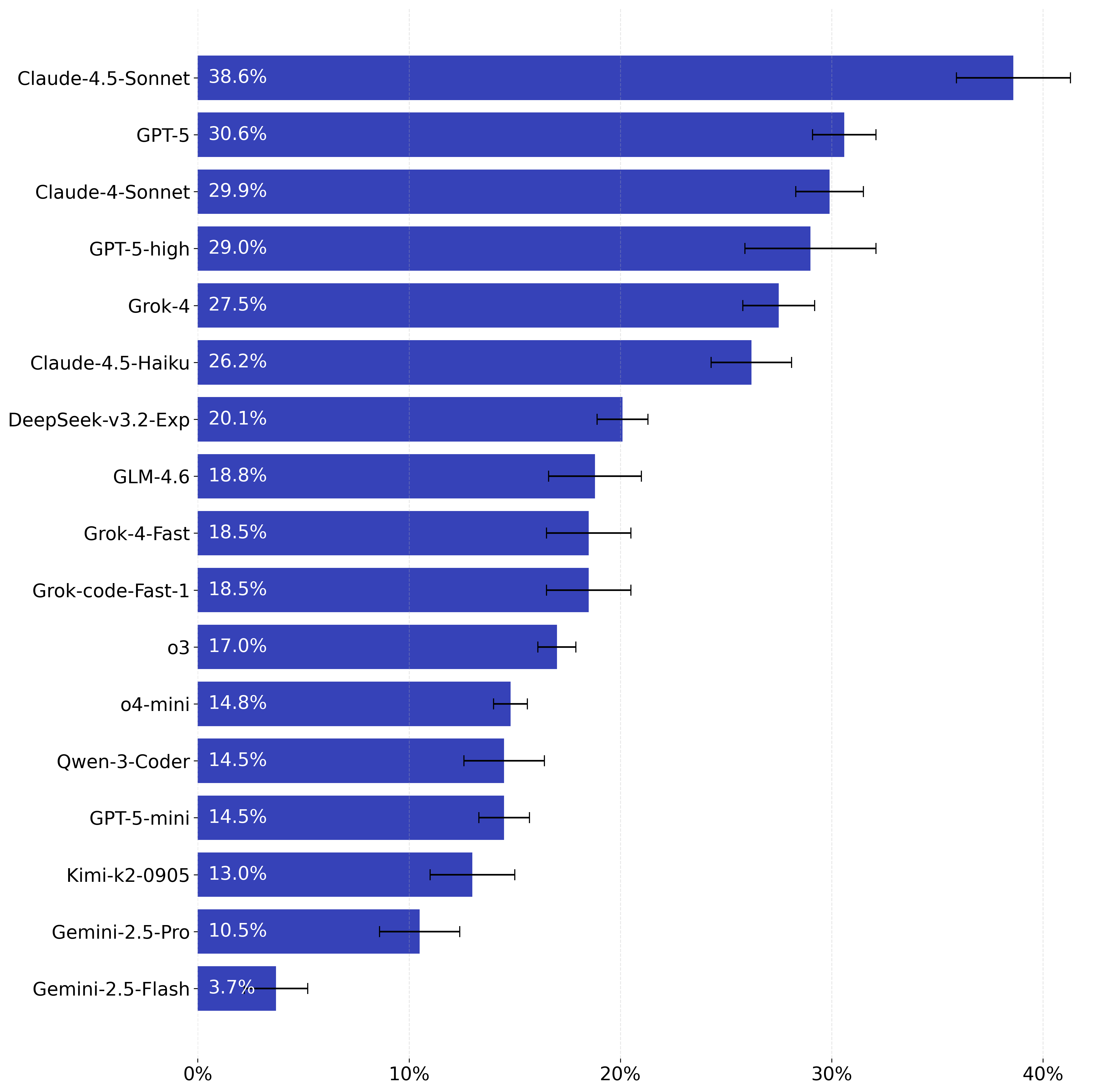
Motivation
Over the past six months, we’ve witnessed remarkable progress in LLM agents. They’ve become significantly more capable in areas such as vibe coding, deep research, and browsing, delivering substantial convenience for users in these domains.However, the real world is not limited to those use cases. Consider a few everyday examples:- As a teaching assistant, you might need to download students’ Python assignments from your email inbox, run the scripts according to a grading rubric, and record the grades in Canvas end‑to‑end.
- As an online shop owner on Shopify/WooCommerce, you might need to identify problematic items in orders, then email the relevant customers with a customized Google Form link for follow‑up.
- As a web developer, you might need to deploy a service to a Kubernetes cluster, test it in a browser, and archive the test report in your remote GitHub repository.
- Tedious and detail‑oriented,
- Hard for non‑experts to pick up quickly, and
- Ubiquitous in everyday workflows across many domains.
- In complex, realistic, and common multi‑step tasks, how do different models actually perform?
- How big are the performance gaps between them?
- Can they really take a loosely defined task and deliver exactly the outcome we expect?
- Integration with 30+ MCP servers (e.g., email, file system, Hugging Face, databases, web browsers, etc.);
- Access to 600+ tools, including both custom-built and standard APIs;
- An average of 20+ interaction turns required to complete each task;
- A fully automated, verifiable scoring script for every task;
- Most tasks start from realistic initial states (not from empty files or blank databases).
- Quick Start
- Framework Overview
- Available MCPs
- Custom Tool Integration
- Task Structure
- Full Task Examples
Model Performance
The Benchmark
Each task in Toolathlon has the following structure:task_config.json file must contain at least the following two properties:needed_mcp_serversspecifies the MCP servers that the agent may use.needed_local_toolsspecifies the custom toolkits that the agent may use.
Task Examples
NVIDIA Market
Analyze NVIDIA’s institutional ownership trends across 8 quarters, adjust for stock split, populate results_template.xlsx with common holdings only.
Experiment Recordings
Update the Notion table with best scores and steps per benchmark from W&B runs, combining same-named runs and averaging available metrics.
Canvas Homework Grader Python
Grade Homework2 by downloading latest Python submissions from email, running them to check for errors, and assigning 10 (pass) or 0 (fail) in Canvas based on correctness.
Toolathlon Framework
To make our evaluation more realistic and easy to use, we designed the toolathlon framework as follows:- Multiple Language Model Support: Compare OpenAI, Anthropic, Google, and open source models through a standardized API.
- Autonomous Agent Design: All functionality is provided as “tools,” and models can manage their execution autonomously through prompts.
- Error Handling: Tool errors do not terminate the task, but instead return an error message, allowing the agent to retry or adjust its strategy.
- Overlong Output Management: Automatically truncates excessively long tool responses and provides paging/search tools to access the full content.
- Context and History Management: Provides tools for querying, deleting, and retrieving history, supporting long tasks that exceed the model context limit.
- Containerized Isolation: Each task can run in a separate Docker/Podman container, ensuring that tasks do not interfere with each other.
- Parallel Execution: Multiple processes batch run tasks, scalable linearly to additional computing resources, and ensuring stable and efficient large-scale evaluation.
- State preservation and verification: Save the complete workspace after the task is completed, and use the script to compare the results with the expectations.