
- English
- 简体中文
In one Toolathlon task, an agent was asked to build a personal website in Notion. The agent-facing instructions listed four required sections. The evaluator, however, checked for five—including an Exhibitions section that the task itself never requested. An agent could follow the written task faithfully and still fail.That is not an agent-capability failure. It is a measurement failure.Today, we are releasing Toolathlon-Verified, a major repair and validation release of Toolathlon. It preserves the original 108-task scope while revising the task definitions, initial states, ground truth, evaluators, and execution infrastructure that turn those tasks into a trustworthy benchmark.
These categories overlap. They describe where the final benchmark snapshot differs, not separate groups of tasks.The development-and-review range from 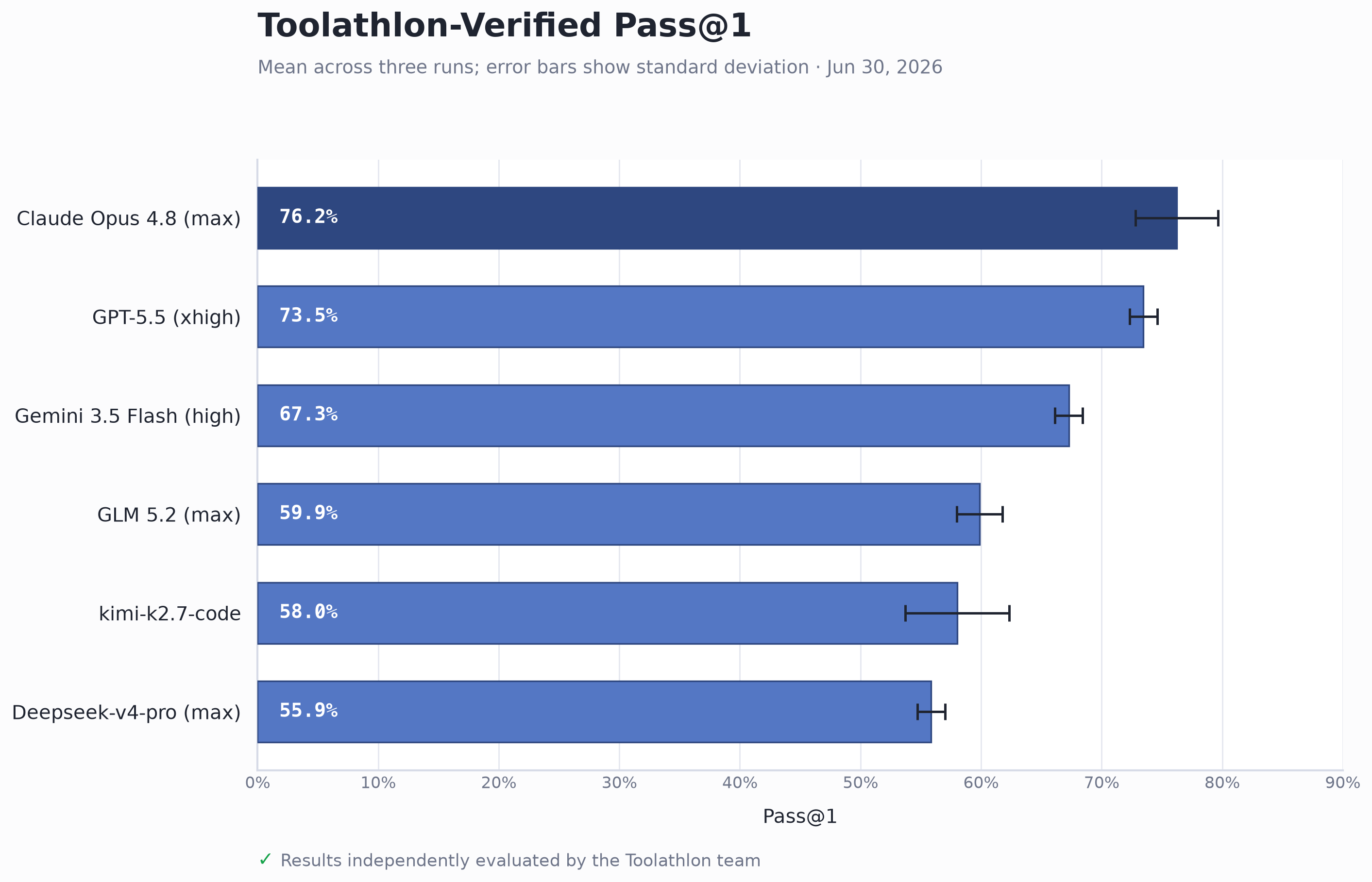
A benchmark failure should point to agent capability—not ambiguous instructions, stale data, brittle formatting checks, leaked state, or an external service that has not propagated yet.
The scale of the update
Toolathlon-Verified is not a new, smaller subset. Both versions contain the same 108 tasks, with no task added, removed, or renamed. Instead, artifacts changed across more than three quarters of the benchmark.| Area | Verified change scope |
|---|---|
| Task packages with net changes | 83 / 108 |
Tasks with changes under evaluation/ | 76 |
Tasks with changes under preprocess/ | 28 |
Tasks with changes under groundtruth_workspace/ | 19 |
Tasks with changes under initial_workspace/ | 14 |
| Tasks with net changes to agent-facing task instructions | 14 |
500e3d86 to the Verified snapshot d57361c0 contains 339 commits: 309 non-merge commits and 30 merge commits. We treat that number as evidence of the engineering and review effort—not as a claim that there were “339 bugs.” The history also includes infrastructure work, model and agent support, documentation, experiments, reviews, and revisions to earlier candidate fixes.A task is a contract, not just a prompt
A long-horizon task is defined by more than its instruction text. The agent must receive a coherent contract across five layers:- what the task asks for;
- what state the environment starts in;
- what tools can actually express;
- what the ground truth records; and
- what the evaluator accepts.
- Cross-region pricing: the iPad education-price task compared prices in Mainland China, the United States, Hong Kong, and Singapore without defining a common currency. The revised task explicitly converts each total to HKD and defines the expected numeric output.
- Invoice completeness: the travel-reimbursement task now defines a complete invoice as one containing an invoice number, tax amount, and description. A missing field or
N/Ais treated as incomplete, and preprocessing preserves missing tax values asN/Arather than rendering them as zero. - Legal revision detection: the revised-terms task now defines a substantive legal change, excludes mere renumbering or relocation, and aligns the prompt, ground truth, and evaluator around the same evidence requirements.
- Time-sensitive requirements: tasks such as language-school research no longer hard-code a quickly expiring application year. They specify the applicant context and how to use current-year information with a controlled fallback.
Correcting errors in both directions
Benchmark errors can reject valid work, but they can also reward incomplete or incorrect work. Toolathlon-Verified addresses both directions.When correct work was rejected
Inlive-transactions, the evaluator called a logging helper with positional arguments. A vestigial parameter shifted the launch time into the log-name parameter, so the check queried the wrong logging target and could reject an otherwise correct run. The fix switched to explicit keyword arguments and added a bounded retry for logging visibility.Other false negatives came from incidental representation details: a trailing newline in a LaTeX file, equivalent timestamps represented in UTC rather than local time, harmless ordering differences, schema aliases, or a remote service returning a newly written object a few seconds late.When incorrect work could pass
Inlanguage-school, a comparison helper returned (is_different, error_message), but the caller tested the tuple directly. Non-empty tuples are truthy in Python, so scalar mismatches could silently evade the failure path. The same task also contained an incorrect CMU IELTS ground-truth value, which was corrected from 7.5 to 7.In apply-phd-email, preprocessing cleared the sender mailbox but not the receiver mailbox read by the evaluator. A correct ZIP attachment left over from an earlier run could therefore make a later, incorrect submission pass. Toolathlon-Verified clears the state that grading actually observes.The goal was not to make graders uniformly more permissive. Candidate changes were accepted, rejected, or partially adopted according to the task contract. Proposals that would have widened the accepted answer space beyond the intended task were rejected or tightened.Reproducible state and trusted grading
Stateful applications make agent evaluation more realistic, but they also create more ways for runs to interfere with one another. Toolathlon-Verified strengthens isolation at both task and grading time:- five previously unseeded preprocessing scripts now use fixed random seeds;
- Kubernetes clusters are namespaced per instance, and Canvas cleanup is limited to task-owned courses;
- affected tasks clear the historical email, application, or service state that could interfere with the current run;
- evaluator, preprocessing, and ground-truth artifacts are withheld from the agent; and
- scoring restores those artifacts from private, hash-checked copies and removes agent-created name collisions first.
- Task contract
- Deterministic setup
- Isolated Agent run
- Trusted grading
- Failure analysis
- Rerun and publish
External-service failures are not agent failures
Toolathlon tasks use real services, so a successful write and an immediately visible read are not always the same event. Toolathlon-Verified separates two failure layers:- Transport reliability: bounded timeouts and retries handle transient connection failures, rate limits, and server errors for services such as Canvas, Notion, WooCommerce, Poste, and Google APIs. Deterministic client errors still fail immediately.
- Evaluation visibility: 43 task evaluators now use shared or equivalent bounded whole-check retries for cases where a service accepted a write but has not exposed it to the grader yet.
A more comparable execution interface
We also added a decoupled execution mode. Preprocessing, MCP services, state, and evaluation remain controlled by the task container, while an agent scaffold can run on the host through a single MCP gateway. This makes it possible to compare different scaffolds without rebuilding the task environment around each one.At the model boundary, Toolathlon normalizes model-visible tool names and handles provider differences in reasoning and tool-call payloads. The intent is not to erase meaningful scaffold differences, but to prevent avoidable protocol quirks from becoming benchmark failures.How we verified the fixes
Toolathlon-Verified was not produced by applying a blanket tolerance rule. Candidate fixes were reviewed against the full task contract—prompt, initial state, available tools, ground truth, and evaluator. Review records include accepted, rejected, and partially accepted changes. In one reconciliation pass, 14 disputed task changes were resolved individually: nine candidate changes were adopted, while five existing implementations were retained or further strengthened.Key failures were traced through real agent submissions, reproduced on the evaluation service, and rerun after repair. Targeted regression tests were added where appropriate across task evaluators, preprocessing, runners, tool adapters, and grading isolation.Finally, we evaluated each of the six reported models across three benchmark runs. The released trajectories expose model messages and tool calls for inspection, while the leaderboard reports final grading outcomes. Together they provide auditable evidence for the benchmark; we do not claim that every published trajectory was manually reviewed line by line.A new Verified baseline
The chart below reports mean Pass@1 across the three runs for each model. Error bars show the across-run standard deviation—not a confidence interval. All six rows use the Default agent configuration and are dated June 30, 2026.